
This article was originally published in German under the title “Vom Informationssilo zum Wissensnetzwerk” by the Open Data Informationsstelle Berlin (ODIS). ODIS is a project of Technologiestiftung Berlin and is funded by the Senate Chancellery of Berlin. The text was translated and adapted for an international audience by Graham Wetherall-Grujić.
A conversation with a bear
In February 2023, Berlin was forced to hold repeat state elections after a court identified “serious systemic flaws” with the original election. Held back in September 2021, it was plagued by long queues, missing ballots, and votes cast after the official deadline of 6 pm. The result of the repeat: The social democratic Mayor Franziska Giffey lost out to the CDU candidate Kai Wegner, who took over as Berlin’s first conservative mayor since the 1990s.
Several weeks after the election, the attention of the German press was caught by the chatbot of Berlin’s service portal, a bear called “Bobbi”. Although Kai Wegner had long since taken over as mayor, Bobbi was adamant that Franziska Giffey still held the office.
Okay then Bobbi, who is the current Mayor of Berlin?
“The current mayor of Berlin is Franziska Giffey.”
Uhh… okay, let’s try it like this: Bobbi, who is Kai Wegner?
“I’m very sorry. I’m afraid I haven’t found an answer to your question.”
(An excerpt from the Tagesspiegel Checkpoint newsletter – ”Artificial impertinence: Berlin’s chatbot Bobbi doesn’t know who Kai Wegner is”.[translated] )
This all happened at the exact moment in time when everyone in the tech industry and beyond was talking about the huge potential presented by the rapid advances in artificial intelligence, driven by chatbots like ChatGPT.
The problem: Garbage in, garbage out
Compared to a botched election, this may seem pretty trivial. Yet as amusing and harmless as the Bobbi incident may seem, it illustrates one thing very clearly. Like any other software or digital tool, chatbots are only as reliable as the information and data fed to them.
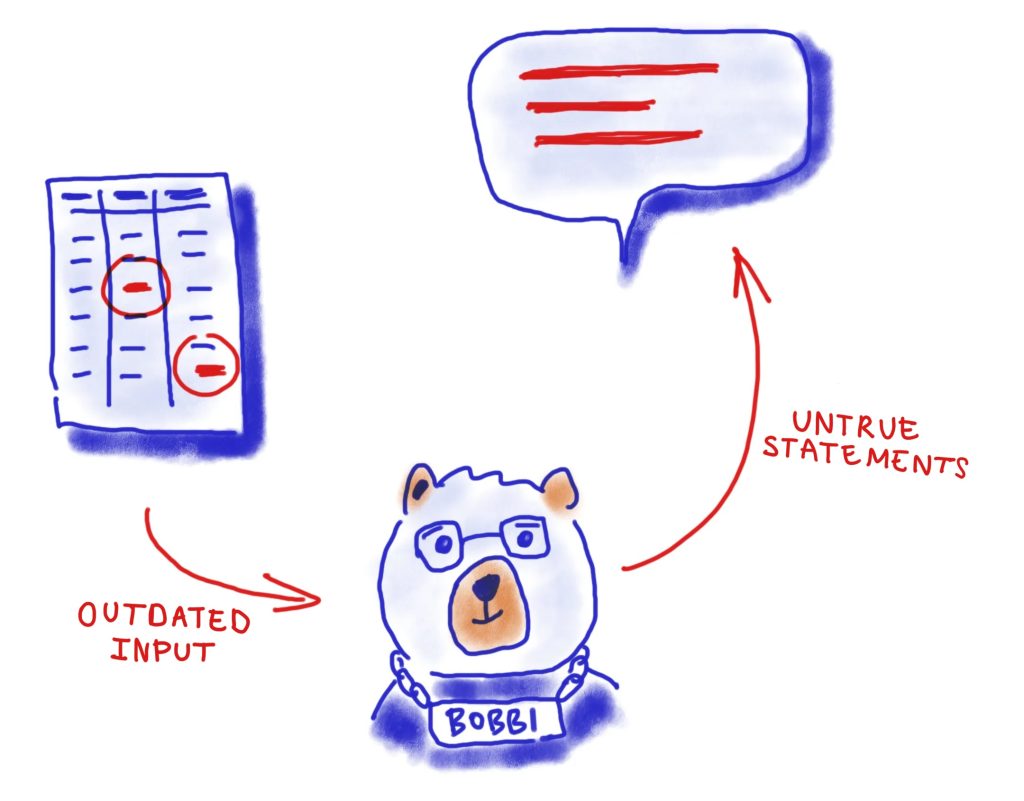
Seen in this light, Bobbi is by no means evidence of a lack of innovation in Berlin. Rather, he illustrates the challenges that digital assistants face when it comes to relevance and accuracy when guiding users. That’s why going forward, the availability of high-quality, up-to-date, machine-readable open data is going to play an ever greater role for innovations within digital ecosystems.
This is why the concept of linked open data is attracting increased attention. It could be used to create a networked, accessible database. This would provide the foundation for chatbots and other digital tools that provide users with accurate, up-to-date information.
In the following, we explore the potential of linked open data, using the example of the organigram tool we developed at ODIS. The project is intended to help move the discussion surrounding linked open data forward. But it also serves as the starting point for the creation of a networked database for Berlin. Bobbi the Bear is by no means the only one who would benefit.
Background
The point of departure: Information silos
Berlin’s administration deals with a huge variety of different topics and tasks. And there is just as much variety in the ways it collects, processes and shares data. There are some areas where they work with standardised machine-readable data – for example in the financial sector. Here, data is essential to the calculations of several different authorities, who use specialised methods to process it.
But in other areas, there are very few guidelines or standardised processes. A good example of this is the documentation of the responsibilities and structures of different parts of the city’s administration. The most important personnel data is represented and published in a decentralised manner. The key information is available in up-to-date form, and can be readily found and viewed online. It is published in PDF format, and doesn’t follow any uniform standard. In short, it is created to be easy to read for human beings, but not for computers.
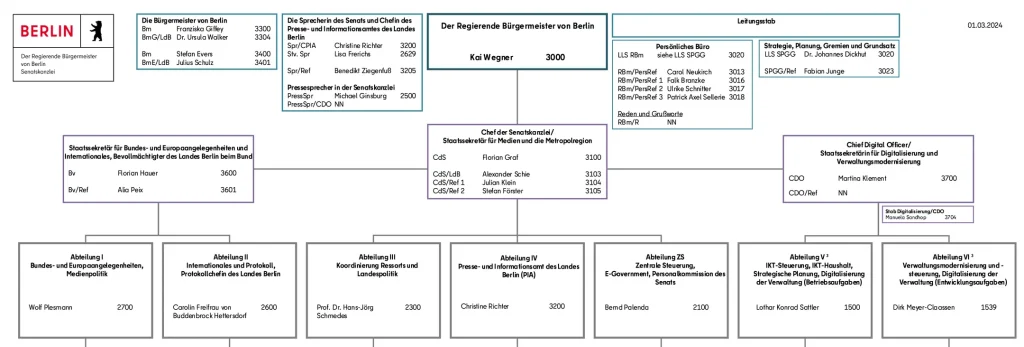
Take the organigram of the Senate Chancellery. For a human being, it only takes a quick glance to identify the “current mayor of Berlin”: Kai Wegner. Franziska Giffey is also featured on the organigram under the title “Mayor of Berlin” (as Wegner’s deputy). Yet for a computer, or the specialist programming languages used by data analysts, this PDF is extremely difficult to read. If the information from the organigram were presented in spreadsheet form, it would be a lot easier for a computer to handle.

Spreadsheets alone are not enough
Yet even spreadsheets have their limits. In the case of the organigram, this is easy to see. The structure of the administration is extremely complex, characterised by hierarchies and dependencies which are hard to sum up in a table.
And there is also another factor which complicates things. The existence of a large number of separate data sets within the administration. Let’s return to our example. Say that alongside the organigram PDF, the Senate Chancellery also publishes a machine-readable spreadsheet listing peoples’ names alongside their positions. A chatbot could use this spreadsheet to answer the question “Who is Franziska Giffey?” with: “The Deputy Mayor of Berlin”. This is correct, as far as it goes. But what the bot doesn’t know is that she also holds the position of Senator for the Economy. This information is not included in the organigram, so the chatbot has no way of knowing about it.
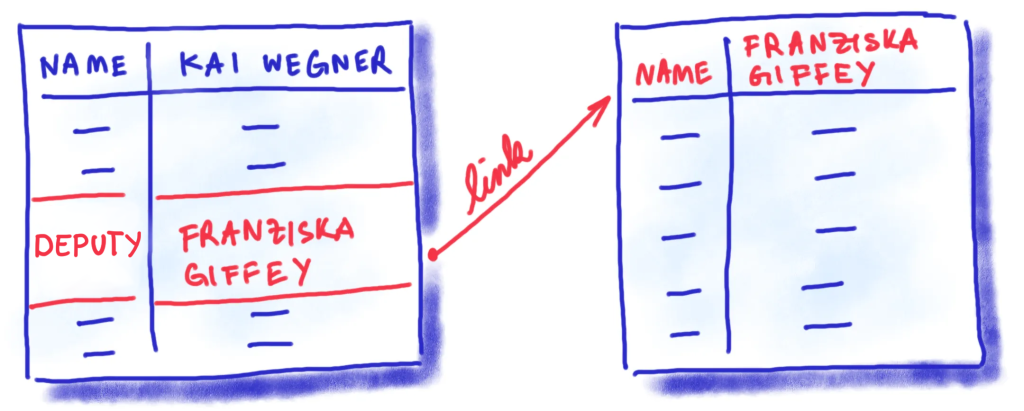
To give comprehensive, reliable answers, the bot needs access to other data sets – in this case, the machine-readable organigram of the Senate Department for the Economy. A chatbot meant to answer a large number of hard-to-predict questions very quickly comes up against its limits here.
The vision: Linked open data as a network of knowledge
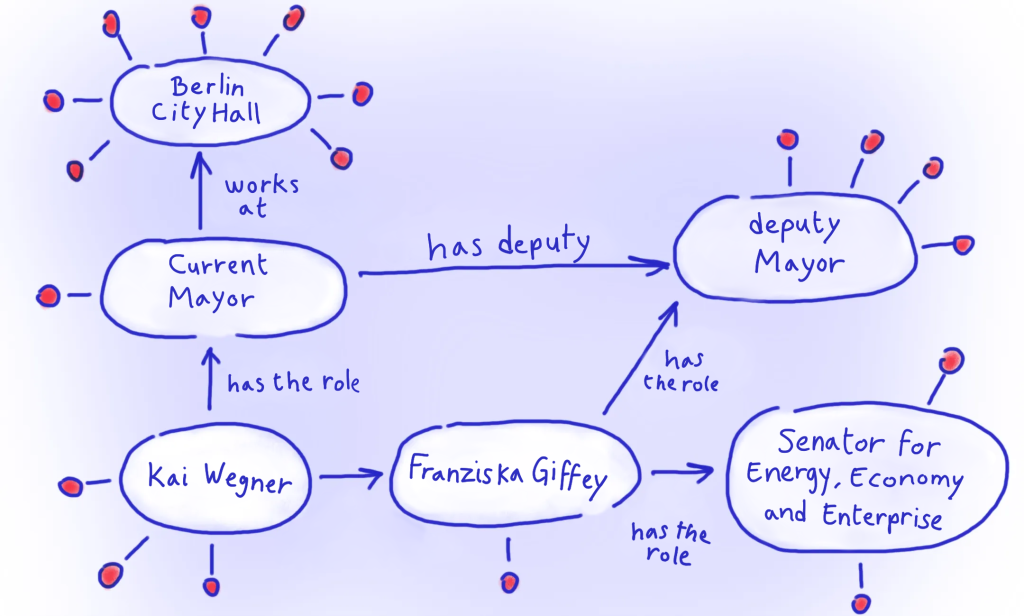
What if there were a way to link together all the information we had about a particular person? Imagine I ask the bot about the current mayor. Not only does it tell me that the mayor is Kai Wegner, but it adds that he took office on 26 April 2023; that he works at Berlin City Hall; that he was born in the Berlin district of Spandau; that the district of Spandau spent €151,046 on childcare in 2023, and so on…
This kind of interconnected data can be created using a special format: Linked open data. The contents inside data sets are labelled using unique identifiers. These can then be used to create foolproof, automatic connections with the contents of other data sets. The result is a network of information, also known as a “knowledge graph”.
By this stage, you might be wondering why all of this is necessary. Aren’t advanced language models like ChatGPT supposed to have just this kind of extensive knowledge? But even ChatGPT was trained using information that is already out-of-date. Linked open data presents a possible solution here. A project in Zurich has demonstrated that ChatGPT does a good job of retrieving up-to-date information from linked open data.
What’s more, a well-constructed knowledge graph can open up a whole new range of questions and knowledge. It doesn’t just help us to keep digital chatbots like Bobbi up to date. It’s also an important foundation for a huge variety of digital applications that are essential to the digitalisation of government.
In the midst of the AI revolution, it isn’t enough for data to be machine-readable. It’s equally crucial that the information is up-to-date, linked, and easy for computers to interpret.
A Linked Open Data Case Study
A prototype tool for creating a machine-readable organigram
At ODIS, we are currently working on an organigram tool with the aim of finding out what kind of key data could form the basis for a knowledge graph in Berlin.
Given the wealth of information they contain about the structure of Berlin’s administration, organigrams are an ideal use case. That’s why in 2023, ODIS developed the Organigram Tool. It allows the information stored in organigrams to be published as linked open data.
Our goals in the project are as follows:
- To study the practical feasibility of linked open data: The project aims to show how linked open data can be put into practice, and what challenges emerge in the process. It gives other people and researchers the chance to experiment with this data and to link it with other data, opening up new possibilities in the area of linked open data.
- To make core data available as linked open data: By creating machine-readable organigrams in linked open data format, we are expanding the currently very limited range of linked data available in Germany. It will only realise its true potential when a critical mass of knowledge arises.
- Development of linked open data standards: Berlin’s new Open Data Strategy includes linked open data as one of its development goals. We want to encourage others in Berlin to develop linked open data. We hope the standards we establish will help them get their bearings, and we encourage them to develop these standards further with us.
In the next section, we explain the most important principles of linked data, and how we have applied them to the organigram.
The principles of linked open data in action
The 5-star deployment scheme for open data developed by Tim Berners-Lee ranges from simple online availability (one star) to full integration into the web of data (five stars). It provides a clear guide to the assessment and improvement of accessibility, as well as the technical usability of data sets.
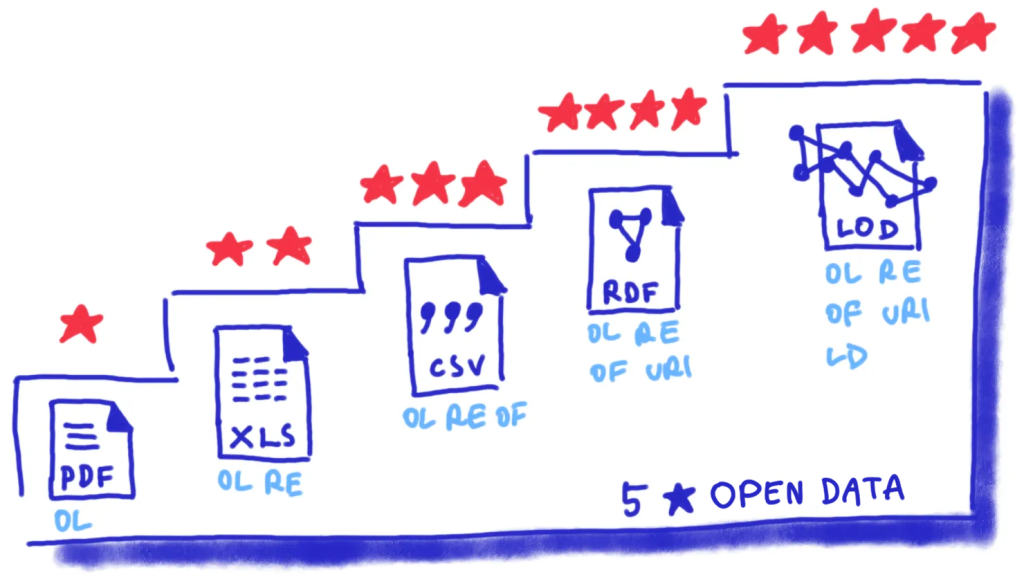
To reach the highest rating of five stars, the data must not only be machine readable; it also has to meet the fundamental principles of linked open data:
- They use URIs to describe objects or people and their properties, and their relationship to one another.
- They are available in RDF format, which presents information in the form of sentences, including a subject, a predicate and an object.
- They use special vocabularies called “ontologies” which define the rules for the kind of relationships are possible between subjects and objects.
- By applying these principles, connections between data sets can be created. For this to be possible, they have to be available online, and in a format that can be interpreted by a special programming language (more on this below).
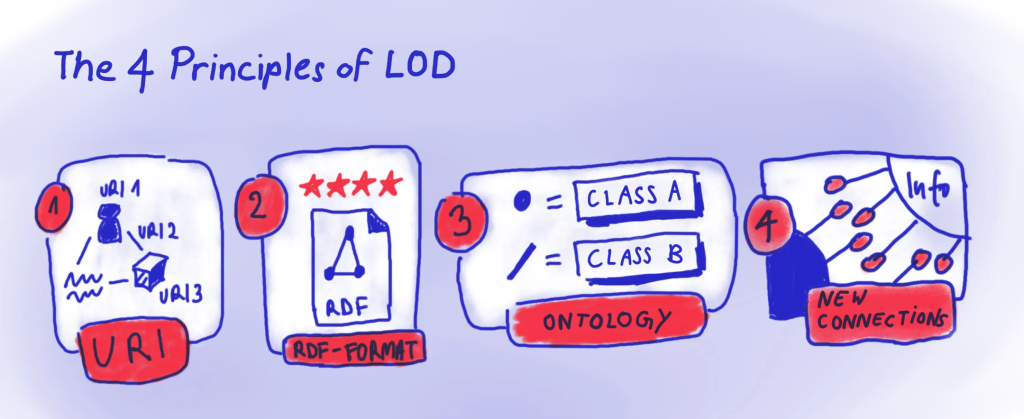
Our organigram tool addresses all four principles. Let’s look at how.
1. The organigram tool as a URI generator and editor
One of the most fundamental requirements for linked open data is being able to identify bits of data. So-called URIs (“Uniform Resource Identifiers”) are used to uniquely identify resources and data on the world wide web, ensuring that they can be easily found, identified, and reused.
URIs do the same thing throughout the internet: They denote abstract or concrete objects, and build the basis for linked data. To make these identifiers accessible, linked open data uses public URIs that can be accessed using HTTP. It isn’t just web resources such as websites, articles or PDF documents that can be given a URI.
Let’s return to our organigram. It isn’t enough to simply create a link to the whole organigram, such as the fictitious URL organigram-senate-chancellery-berlin.de. The individual elements within the organigram also have to be given a unique identifier. That means that every individual senator, department, administrator or organisation gets its own URI.
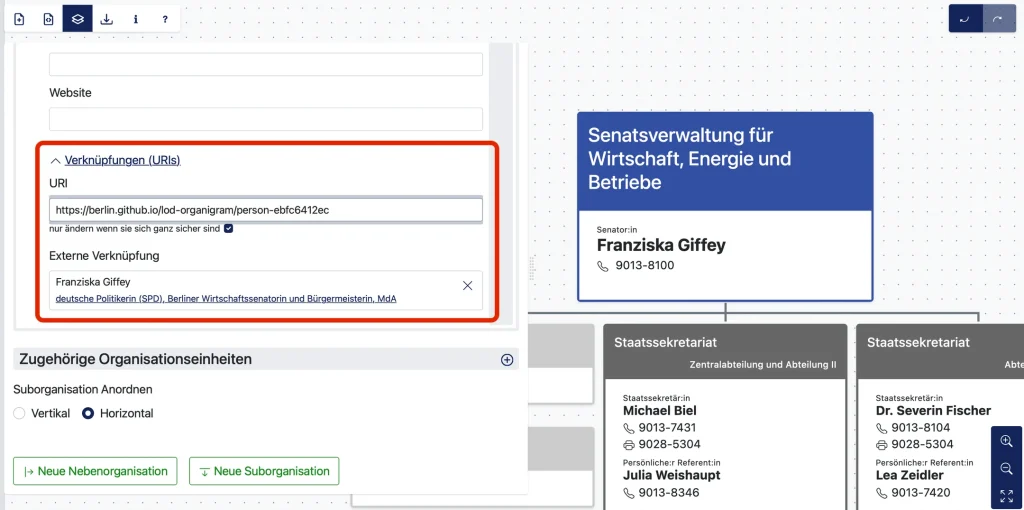
When an organigram is created using our tool, it automatically generates a URI for every single object (or person). The URIs can also be added or edited manually. The tool also offers the possibility to connect to pre-existing URIs from the open database wikidata. We’ll look at why that matters later.
2. Exporting RDF as triples
We saw above that in linked open data, information is stored in the form of three-part sentences. These so-called “triples” consist of a subject, a predicate, and an object. For example, “Kai Wegner” “is” “the Mayor of Berlin”); or “Kai Wegner” “works at” “Berlin City Hall”.
The subject comes first, and tells us what the statement in question is about. In our example, it’s the person Kai Wegner. The object is a value or another resource that the subject is related to – in our examples, “Mayor of Berlin”, or “Berlin City Hall”. It comes at the end of the sentence.
The predicate sits in between the subject and the object. It defines the relationship between them. One of the most common predicates is the word “is”, denoting identity, as in our first example, “Kai Wegner is the Mayor of Berlin”. But depending on the kind of data in question, we will need to express all different kinds of relationships. In our case, the predicate “works at” will be useful.
The subject, object and predicate are all identified using a URI.
Example triples
Some information stored as a triple and coded using URIs might look like this:

(Subject: URI for the organisation SenWEB)

(Predicate: URI for the role “Senator”)

(Object: URI for the person Franziska Giffey)
Statement: Franziska Giffey is the senator for Economy, Energy and Enterprise.
URIs can be used like this to create connections within our data set. But if these same URIs are used in other data sets, they can also be used to create connections between data sets. Franziska Giffey features in our organigram of the Senate Chancellery in her role as deputy mayor. But she also features in the SenWEB organigram as senator for the economy. As long as the same URI (person-f60db6579cc) is used in both sets, the information about her different roles can be connected.
A data set contains a large number of such triples. They are saved in a special data format, an RDF file. An organigram created with our organigram tool can be downloaded as an RDF.
3. A custom ontology for Berlin organigrams
Linked data also requires the use of standardised ontologies, a kind of specialised vocabulary. They provide the rules for the kinds of objects a data set contains, and the kind of relationships between them. Ontologies can be understood as schemas which define the structure and meaning of data in a particular context. They allow computer programmes to “understand” the meaning of data.
One example of a pre-existing ontology which is often used for descriptions of people is called vCard. An online article describes how the ontology is used, and provides an overview of its concepts – in other words, of the kinds of information and relationships that can be depicted using the vocabulary. In the case of vCard, that includes the name, address, contact details of the person in question. The ontology provides URIs necessary to express information in the form of triples.
Our Organigram Tool uses both existing vocabularies as well as a special one developed for Berlin. To accurately capture the relationships between different departments and employees, ODIS developed a custom ontology. Our web entry in the form of a GitHub-repository defines institutions and positions specific to Berlin, and provides the relevant URIs, for example for the role “Senator”.
Linking the data
The organigram tool makes it possible to create and download data sets in RDF format in accordance with predetermined standards. But to qualify as linked open data, you have to go one step further: Making the data available online so that it can be retrieved and linked to other data. This requires a special kind of database known as a “triple store”. A triple store makes efficient management and retrieval of linked data possible by saving the triples, thereby preserving the relationships between different data points. To interpret the information in a triple store, a special query language called SPARQL is used. The result of an enquiry is typically displayed as a table containing a series of triples with information about the person in question.
A query that returns a list of all the senators in Berlin might look like this:

The query searches for entities (?person), and retrieves their first names, surname, position and the Wikidata URI. It then filters for people with the position “Senator”, defined in our ontology.
In the second part of the query, the true potential of linked data becomes apparent. Here, a link to the Wikidata database is created, returning a picture (?image) of the senator in question. Although the image is not contained in our original data set, linked data allows us to find a picture labelled with the same URI saved elsewhere on the web.
Linked Open Data, AI and LLMs
LLMs such as ChatGPT (the model is actually GPT-4) could play a role in making the data more accessible. They can both write and interpret code. This means you could type a question in ordinary English, and the LLM will convert it into a SPARQL query. After running the query automatically, it then return the results in an easy-to-read format. This makes linked open data considerably more accessible, since users will no longer have to interact directly with a complex query language.
A real-world example of this is the ZüriLinkedGPT, which enables users to query the Linked Data Triple Store of the city of Zurich using natural language. LLMs can also help process newly generated data, for example fast creation of applications or analyses, as the following screencast illustrates.
Summary and prospects for linked open data
What’s next
Our aim for this case study was to use a practical example to explore the potential and the challenges of using linked open data in Berlin. The organigram tool helped to create new competencies, but it was also intended as a kind of pilot project. So far, we used the tool to create prototype organigrams for four different senate administrations, making them available in the triple store for testing and demonstration purposes.
Our aim is to work with all of the senate administrations to make organigrams for them. At the same time, the ontology will be iteratively improved and expanded. Beyond that, of course, other authorities can use the tool, both in Berlin and beyond. Ultimately, it’s a learning project intended to contribute to the development of data management, infrastructure and availability.
Focus
Originally, the organigram tool was intended to be used to both replace and standardise PDF organigrams (it can create PDF exports). But in the tests and feedback loops with the relevant people at the senate administrations, it became apparent that the requirements for graphical representation in organigrams is extremely hard to combine with the requirements for a machine-readable, structured file. It is not currently possible to preserve all of the visual subtleties that can be created using tools like Powerpoint. As such, the organigram tool is primarily used to create manageable, up-to-date data sets.
Other linked open data projects
To really explore the potential and challenges of linked open data, we need to reach a critical mass of data sets. So far, very little linked open data about Berlin is available.
If in future, a critical mass of data sets are going to be connected, and new insights won and innovative solutions for complex problems developed, we need a growing pool of linked open data. So far, very few linked open data about Berlin is available. One example is Berlin’s Living-Oriented Spaces (LOR) of Berlin, geographic subdivisions which serve as the foundation for planning, prognosis and observation of demographic and social developments. Via GitHub, users can view these subdivisions, from an overview of all districts to the smallest subdivisions, for example “Zwinglistraße” in the Mitte district (Planungsraum 01022105). The population data for the city are also available as linked data.
As part of the fourth annual national plan of action, The Berlin senate administration for finance has committed to publish its two-year budget as linked data in RDF format. With thousands of details of incomes and expenditures, the budget contains important information with high local and political relevance.
The standardised publication of data in RDF format could create a connection between machine-readable organigrams, the LOR and the budget data. This could lead to new insights on the Berlin administration, its organisation and its finances, without the need for time-intensive processes involved in combining data sets manually. The project is planned for 2024, and will build on top of our ontology. This means the projects will speak a common “language”, and the data can all be linked.
A call for sparring partners!
If you have any questions or feedback on our organigram case study, or ideas for other possible linked open data projects, we’d love to hear from you. We want to travel the path towards 5 star linked open data together with the community and the authorities. ODIS invites anyone who is interested to explore new approaches and gather new insights with us. You can get in touch with us at odis@ts.berlin
Like chabot Bobbi, we can’t wait to see what happens next in the world of linked open data.
